本文共 3521 字,大约阅读时间需要 11 分钟。
一、logback和log4j2压测比较
1、logback压测数据
logback压测数据,50个线程,500万条日志写入时间。
logback:messageSize = 5000000,threadSize = 50,costTime = 27383ms logback:messageSize = 5000000,threadSize = 50,costTime = 26391ms logback:messageSize = 5000000,threadSize = 50,costTime = 25373ms logback:messageSize = 5000000,threadSize = 50,costTime = 25636ms logback:messageSize = 5000000,threadSize = 50,costTime = 25525ms logback:messageSize = 5000000,threadSize = 50,costTime = 25775ms logback:messageSize = 5000000,threadSize = 50,costTime = 27056ms logback:messageSize = 5000000,threadSize = 50,costTime = 25741ms logback:messageSize = 5000000,threadSize = 50,costTime = 25707ms logback:messageSize = 5000000,threadSize = 50,costTime = 25619ms 说明:
这个是logback日志的压测数据,在开发机(双核四线程),高配开发机(四核八线程)和服务器(32核)压测的效率都差不多,而且线程开多的时候,性能反而有下降,压测数据如下:logback:messageSize = 5000000,threadSize = 100,costTime = 33376ms
这个是在32核机器上压测的平均值,高于开发机。
2、log4j2压测数据
log4j2压测数据,因测试数据会占用一些篇幅,这里仅取中位数,但上下差距并不大
log4j2:messageSize = 5000000,threadSize = 100,costTime = 15509ms ---开发机 log4j2:messageSize = 5000000,threadSize = 100,costTime = 5042ms ---高配开发机 log4j2:messageSize = 5000000,threadSize = 100,costTime = 3832ms ---服务器 本次压测,基本上与log4j2官网数据吻合,经过验证异步日志确实可以极大的提高IO效率
下图为同步、异步、只异步appender的性能对比
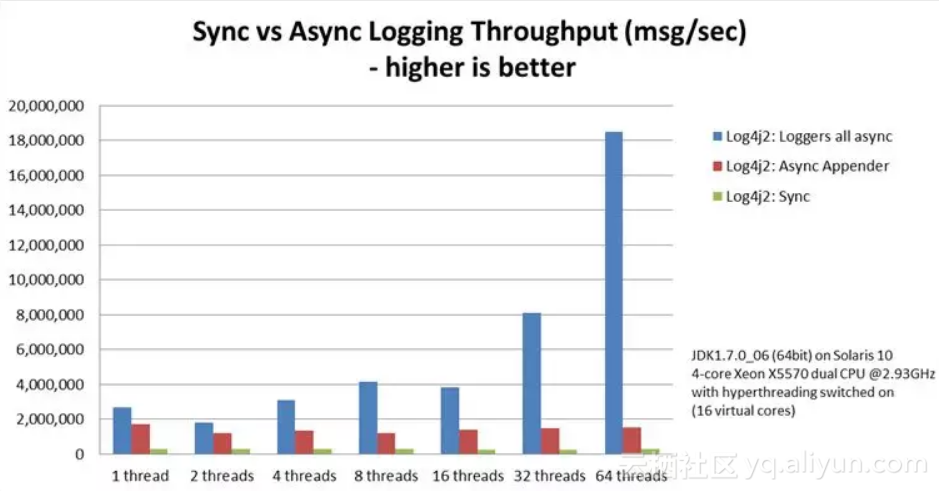
Async loggers have much higher throughput than sync loggers.
和其他日志框架的对比:
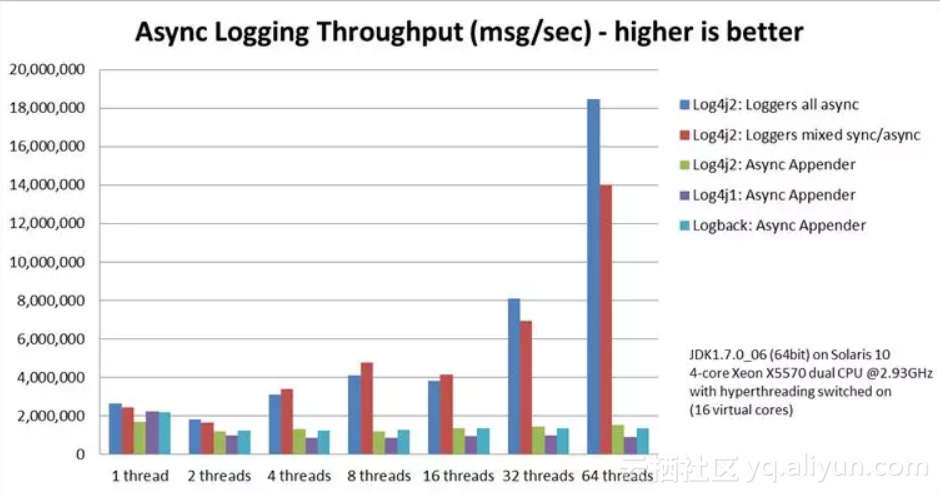
Async loggers have the highest throughput.
从本次压测中,也得知确实在同步日志写到一定程度下,会大大的影响服务器的吞吐率,各位同学可以根据自己项目的情况,做日志上的优化。
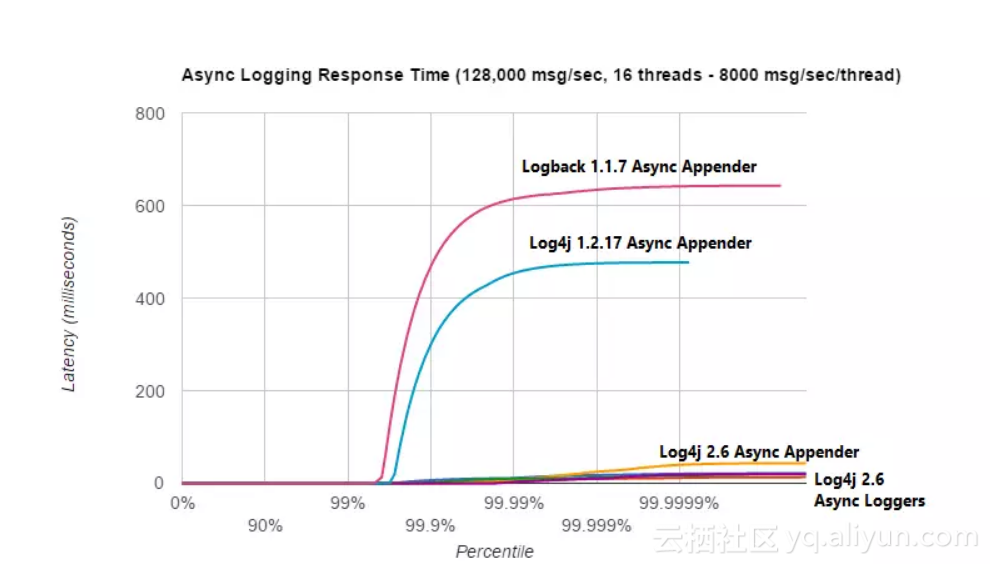
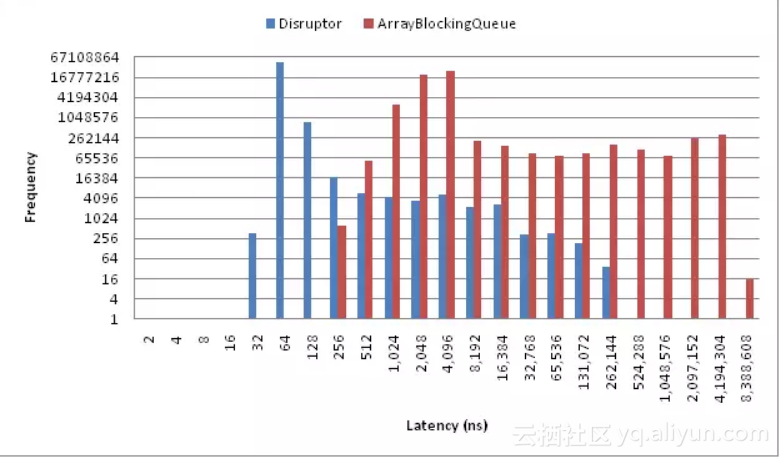
下图为并发量大时,日志框架对系统吞吐率产生的影响,这里看logback和log4j确实影响很大,但实际情况中,感受到的要远远小于此图。
二、压测配置
log4j2的效率可以在多线程时,在线程数量大的情况下,超过logback10倍左右!500万数据大概0.25G,只需3秒左右就可以写进磁盘。
在配置上,首先第一条建议是如果做异步,那么所有的日志都是异步写,这样的性能指数的增长是量级的。当然也可以混合部署,但是性能影响就没有全部异步这么明显。
配置上,优化一定的属性,对性能也有一定的影响。
log4j2本身提供了20多种appender供使用者选用,但一般开发中采用的就是RollingRandomAccessFile,该组件有多个属性配置,常用的做一下说明(其他配置对性能意义不大,有兴趣的同学可自己去官网查看)

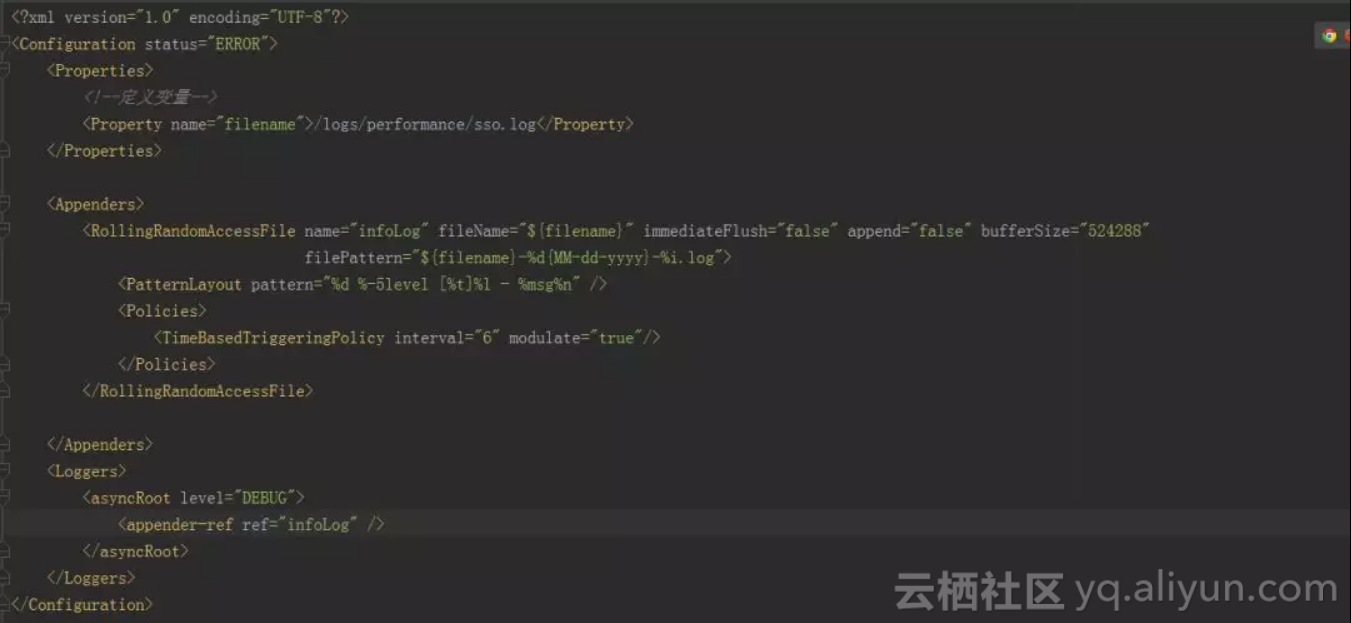
在asyncRoot中可以添加includeLocation="true"属性,该属性如果为true,可以携带类名和行号等信息,但是抽取这些信息,会有一些性能损耗
log4j2改版以后,组件和功能极大丰富,有兴趣的同学可以去官网http://logging.apache.org/log4j/2.x/manual/index.html或找我来一起交流。
三、disruptor队列
查看底层代码,log4j2之所以能在异步写日志时性能提高这么多,离不开优秀的mq组件disruptor。
目前使用该队列的知名软件包括但不限于Apache Storm、Camel、Log4j 2。
由于时间有限,本篇着重讲解底层队列的实现,因为这个对性能的影响是最大的。
以此图为例:
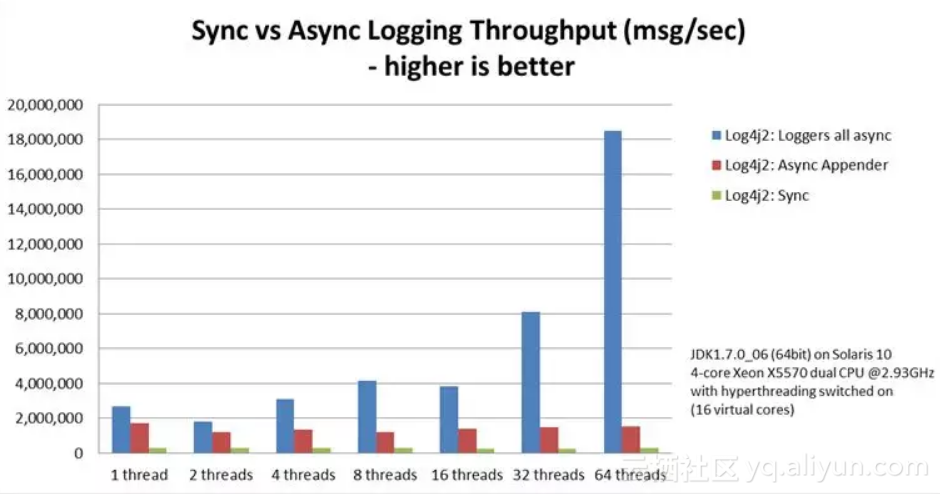
Async loggers have much higher throughput than sync loggers.
同步性能最差,异步全局异步的性能接近异步appender的10倍,同样是异步实现的,为何性能有如此大的差距?
去看源码:
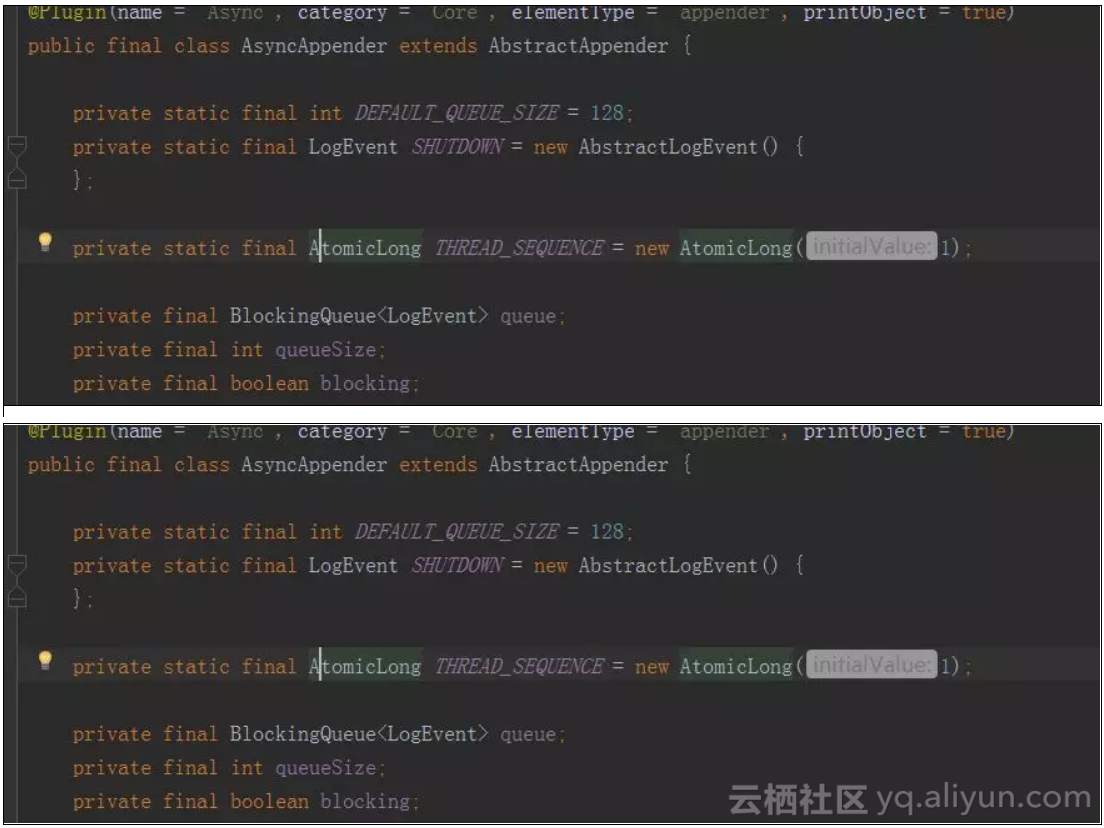
以上是异步Appender的实现,可以看到,内部内置了一个BlockingQueue队列,具体实现采用了ArrayBlockingQueue
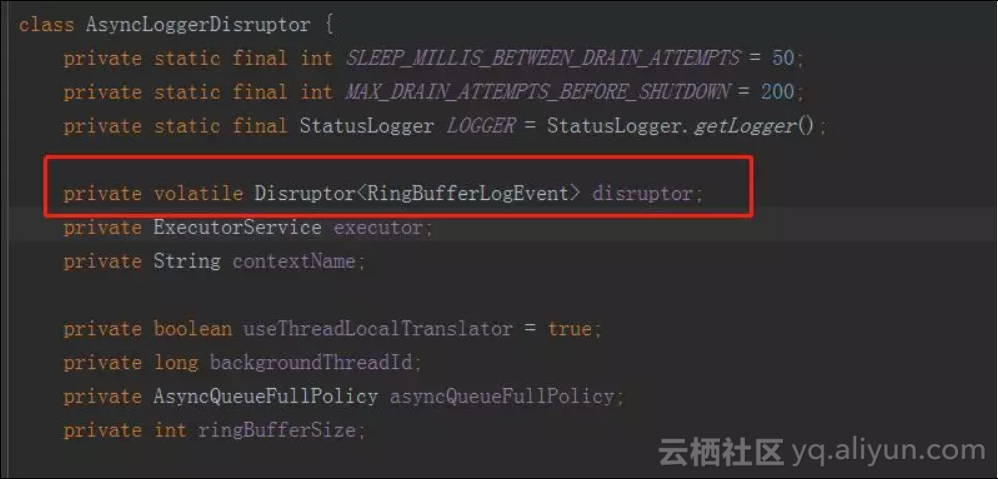
接着是全局异步loggers的实现方式,可见内部的队列使用的是disruptor。
性能上的优劣,绝大部分原因都是数据模型的问题,往下我们分析一下BlockingQueue和disruptor的实现方式,由于篇幅有限,从JDK源码来看:
1、ArrayBlockingQueue
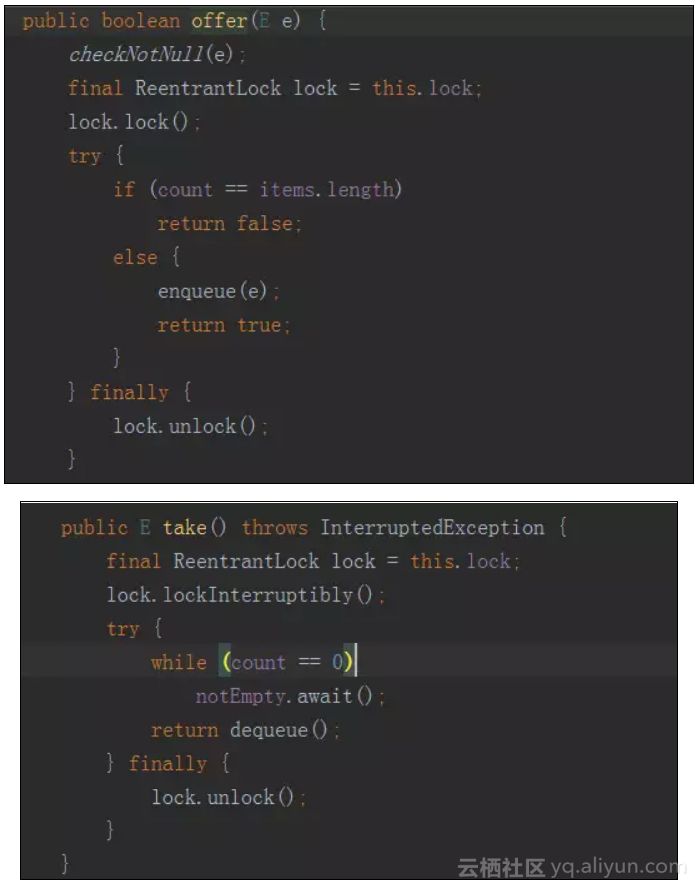
可以看到ArrayBlockingQueue采用的是加锁的方式来处理线程安全问题的。
加锁的问题,虽然历代JDK一直投入大量的精力去解决问题,比如优化Sync关键字的实现方式、添加读写锁等,但是由于结构特性的问题,一直无法从根本上解决性能开销问题。
题外话 _ 除了锁的问题,还牵涉到底层CPU在计算时读取内存数据的问题。
举个例子:当你遍历一个数组时(数组在CPU计算时,是简单数据结构),你读取到第一个元素时,其他元素也会相应的放入1级缓存(距离CPU最近),所以你遍历数据的方式是最快的,这就是简单数据结构的优势。
但是如果你在操作一个Queue时,一般会涉及几个变量,这里以ArrayBlockingQueue为例:
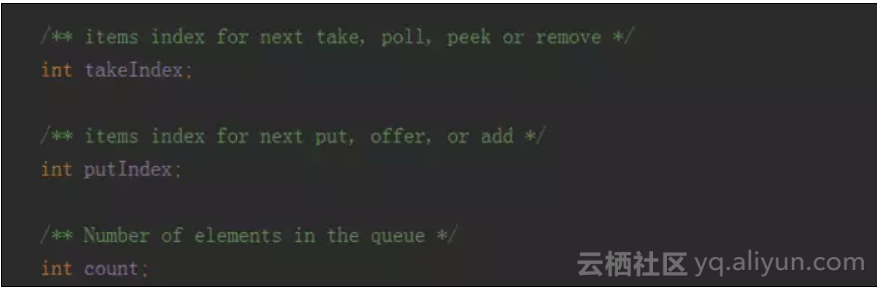
这里有三个变量,分别代表了下一个要出的元素下标,要进的元素下标和长度
当然,这几个简单类型是非常容易放入1级缓存并进行高速计算的,但是问题是,这个Queue是一个生产者和消费者的模型,牵涉到两端操作,于是当生产者写入元素时,takeIndex和putIndex数值发生改变,消费者在消费时要拿的takeIndex也跟着改变,这时就需要去主存中重新去取takeIndex,而无法利用1级缓存进行高速计算。
以上大致解释了ArrayBlockingQueue的性能劣势,接下来就看disputor如果解决这些问题。
2、Disputor
引入官网的一段话(首先要明白背景和诉求):

这里的表述和我们的目标一致,都是要解决锁和缓存缺失带来的性能开销问题。
引用几张官网的截图(风格还比较有趣):
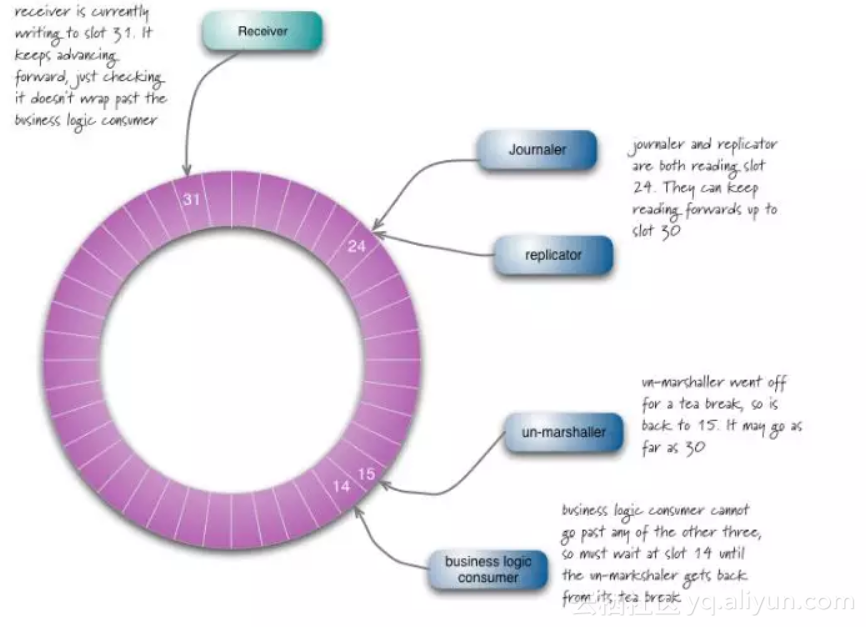
https://www.slideshare.net/trishagee/introduction-to-the-disruptor?from=new_upload_email 这是该PPT的地址,有兴趣的同学可以关注下。
他们采用了环形数据结构来解决这个问题(他们称之为魔法圆环,或魔法圆圈之类的),此种数据结构的有点是,不需要记录额外的下标,直接由JNI返回可以操作的地址,然后当多线程并发读写的时候,使用的也是CAS方式。
这样,不能使用1级缓存和加锁操作的问题就解决了(关于CAS大家可自行谷歌,有非常多的文章来介绍)。
由于篇幅和经历有限,本次分享先写到这里,如果之后对disruptor有需要的话,可以再次深入研究。
原文发布时间为:2018-08-15
本文作者:詹嵩
本文来自云栖社区合作伙伴“”,了解相关信息可以关注“”。
转载地址:http://xwjio.baihongyu.com/